【滴滴 HierETA】Interpreting Trajectories from Multiple Views A Hierarchical Self-Attention Network for Estimating the Time of Arrival
滴滴和华南理工在 2022 年 KDD 上发表的 ETA 论文,从多个视角解释轨迹,引入 Hierarchical Self-Attention Network 方法进行建模,最终在滴滴内部数据集上获得指标提升。
关键信息
- 论文地址:Interpreting Trajectories from Multiple Views: A Hierarchical Self-Attention Network for Estimating the Time of Arrival | Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
- 关键字:网约车 ETA、轨迹挖掘、Self-Attention
背景信息
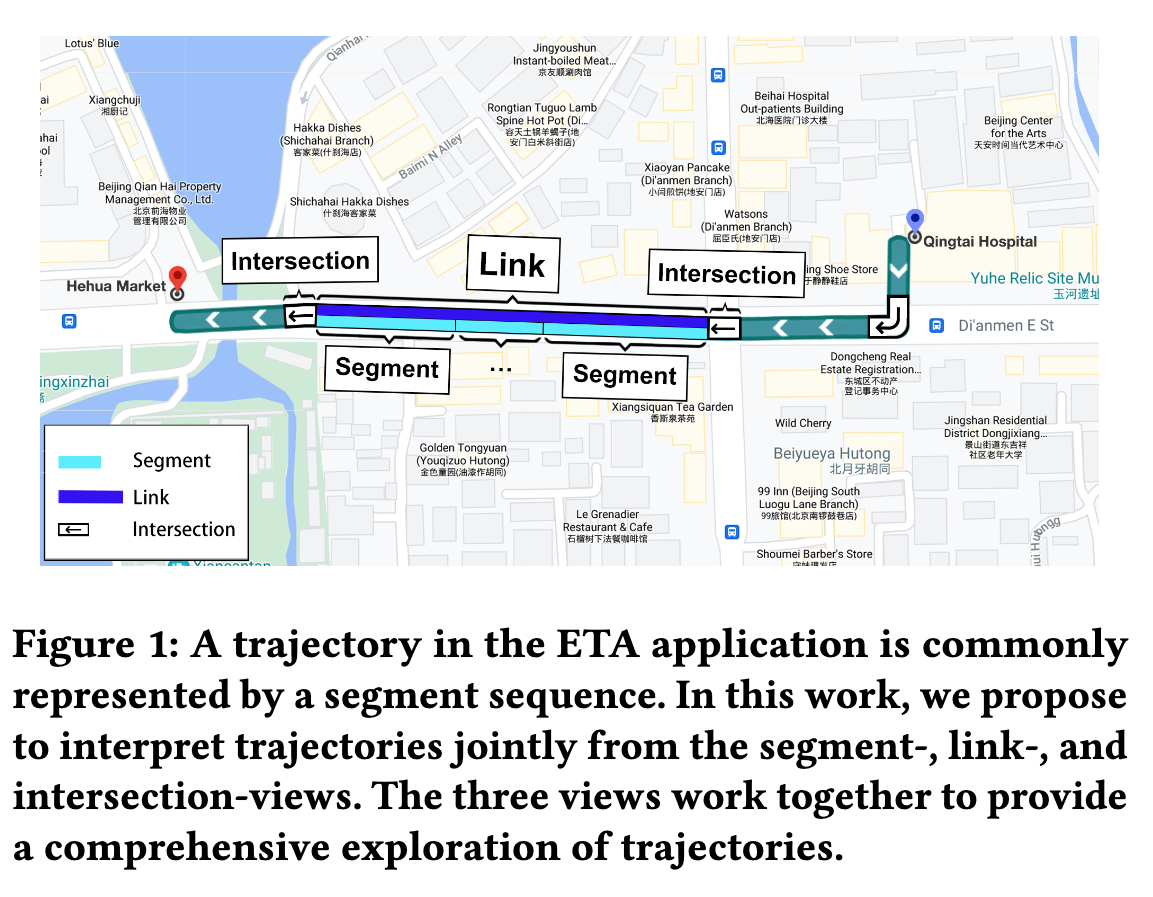
下图是一个行程的轨迹(trajectory)示意图,任务是预测整个行程的到达时间。作者提出三种视图:
Intersection-view对应现实世界中的路口,其属性包括:红绿灯等待时间、交通灯数量、历史车通过流量。link-view连接两个路口的路,其静态属性包括:是否收费、道路宽度、道路等级。segment-view人工将 link 打断成多个小段,用来表示细粒度的局部交通情况(红绿灯前一条路可能不是全部拥堵,用segment来表示比link来表示更合理),但是在表征道路网络结构方面并不完全。
核心问题
- 传统 ETA 方法采用分治策略,将一个轨迹拆分成多个小段(segment-view),然后累加每个小段预测结果得到最终 ETA(实验结果中的 Route-ETA),显然这种策略会导致较大的累积误差。
- 多视图(Intersection、link、segment)建模困难,常规方法使用 segment 建模,不考虑 link,没有对同一个 link 多个段之间的一致性进行建模。
- link 和 Intersection 的属性不一致,很难使用同一个网络去建模。
相关工作
文章中引用的相关工作主要包括三个方面:交通流预估(traffic flow prediction)、到达时间预估(travel time estimation)、自注意力机制。
- GMAN:基于图的多注意力机制来预测交通状况
- 图学习通常会受到不相关的空间领域的负面影响(关注的区域越大月明显),并且这种影响会在训练过程中传播。
- 图建模被限制在很小的区域范围,在大规模城市系统中存在不足
- DeepTTE:原始 GPS 轨迹序列 + geo convolutional network + LSTM
- (WDR) Learning to Estimate the Travel Time:Wide & Deep & RNN
- ConSTGAT 和 CompactETA 图建模 ETA
- DeepGTT: 深度生成模型学习 ETA 分布
- HetETA :multi-relational network 学习时空数据表示
- TTPNet:利用张量分解和图 embedding 从历史轨迹中学习速度和 emebdding
核心贡献
- 利用三个视图的层次关系对道路底层结构进行建模
- 分层自自注意力网络
Hierarchical Self-Attention Network - 自适应自注意力网络
Adaptive Self-Attention Network
解决方案
模型结构分成三部分:Segment Encoder、Joint Link-Intersection Encoder 和 Hierachy-Aware Attention Decoder
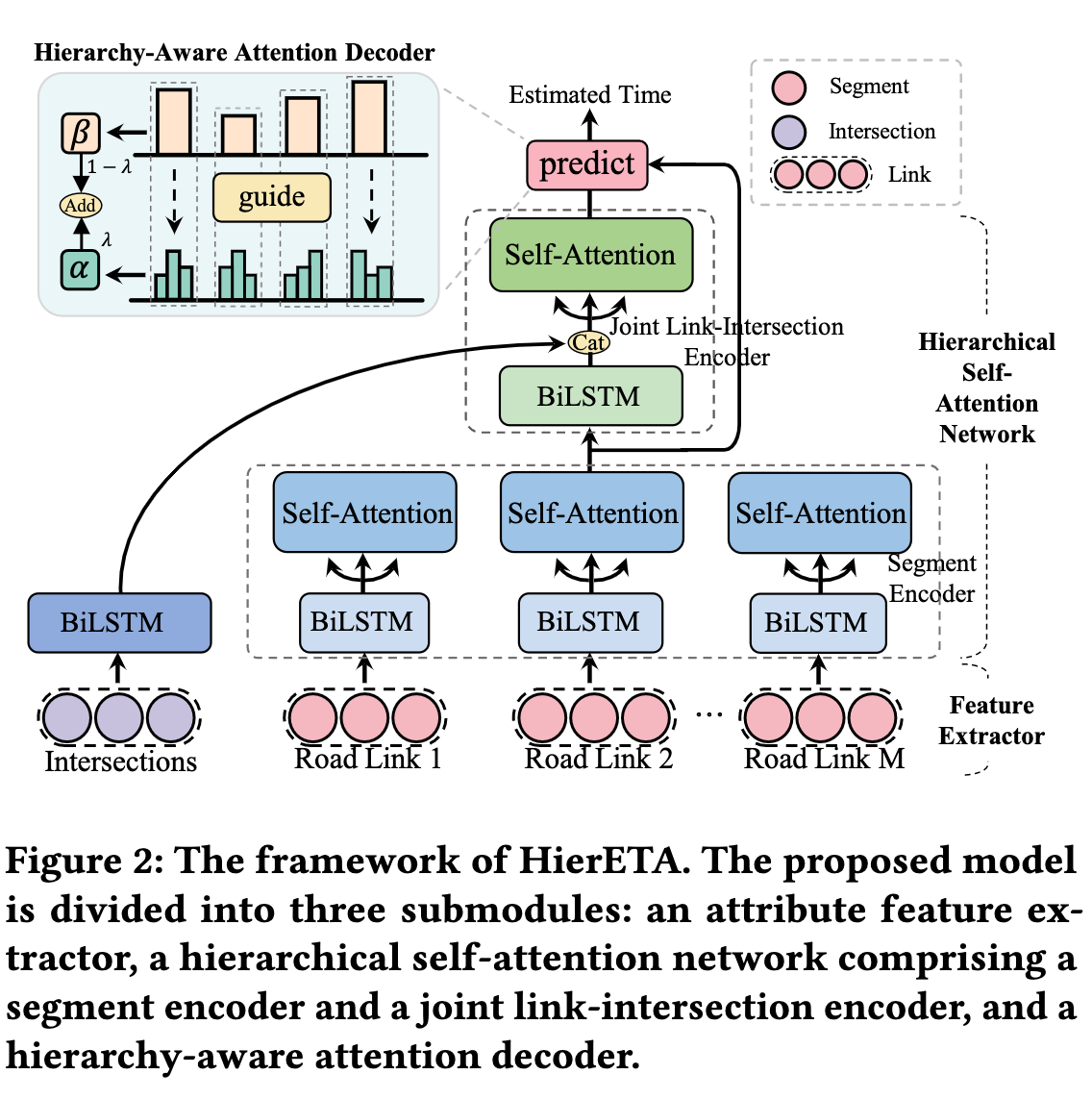
Segment Encoder
这个编码器主要作用是对同一个 link 的 sgement 进行时空建模:
- segment 特征是 ,全局特征是
- 利用 BiLSTM 处理 ,正向和反向结果 concat 成 segment 的表示 。
- 同一个 link 内 segement 记作
- 计算 j-th segment 和 link 内其他 segment 的全局相似度
- 计算 j-th segment 相邻 个 segment 计算局部相似度
local sematic pattern,这一步是捕获局部 segment 的依然,对拥堵转移进行建模。 - 用门控机制平衡全局和局部相似度的结果
- 控制参数通过 学习
- 所有 link 的 encoder 参数共享以及并行计算
Joint Link-Intersection Encoder
上一个解码器主要在 segment-view 上建模,缺少对 link 之间一致性建模,Joint Link-Intersection Encoder 考虑 link 和 intersection 交替出现的特点(一条路连接两个路口),同时在 link-view 和 intersection-view 维度建模,实现通过 segment-view 捕捉局部交通信息, link-intersection context 捕捉道路属性:
- 加权融合 segment 表示得到 link 表示
- 权重计算方法 [[Attention]]
- 得到 link 和 intersections 的表示后,分别用两个不同的 BiLSTM 编码(主要让两个向量长度相同)得到 和 ,concat 在一起得到
- 经过 self-attention layer + resnet + ln 得到
- 考虑到相邻 link 之间的交通影响更加弱和稀疏,作者没有计算不同 link 之间的 local pattern,从而避免过拟合。
Hierachy-Aware Attention Decoder 层次感知注意力解码器
一个行程中不同的 sub-route 对于 eta 贡献是不一样的(比如拥堵的路口和道路对时间预估影响更大),引入层次感知注意力来计算最终 ETA:
- 和 分别是 segment 和 link-intersection 的表示
- link 的注意力 ,且 (xr 是全局特征)
- 计算 segment 之间注意力 ,其中 是 link 重要性,实现在计算 segement 之间的重要性时,模型也能参考 link 重要性。
Hierachy-Aware Attention Decoder 让整个模型自适应选择不同表示粒度中最相关的特征(可以是几个 link 权重大,还是几个)
实验结论
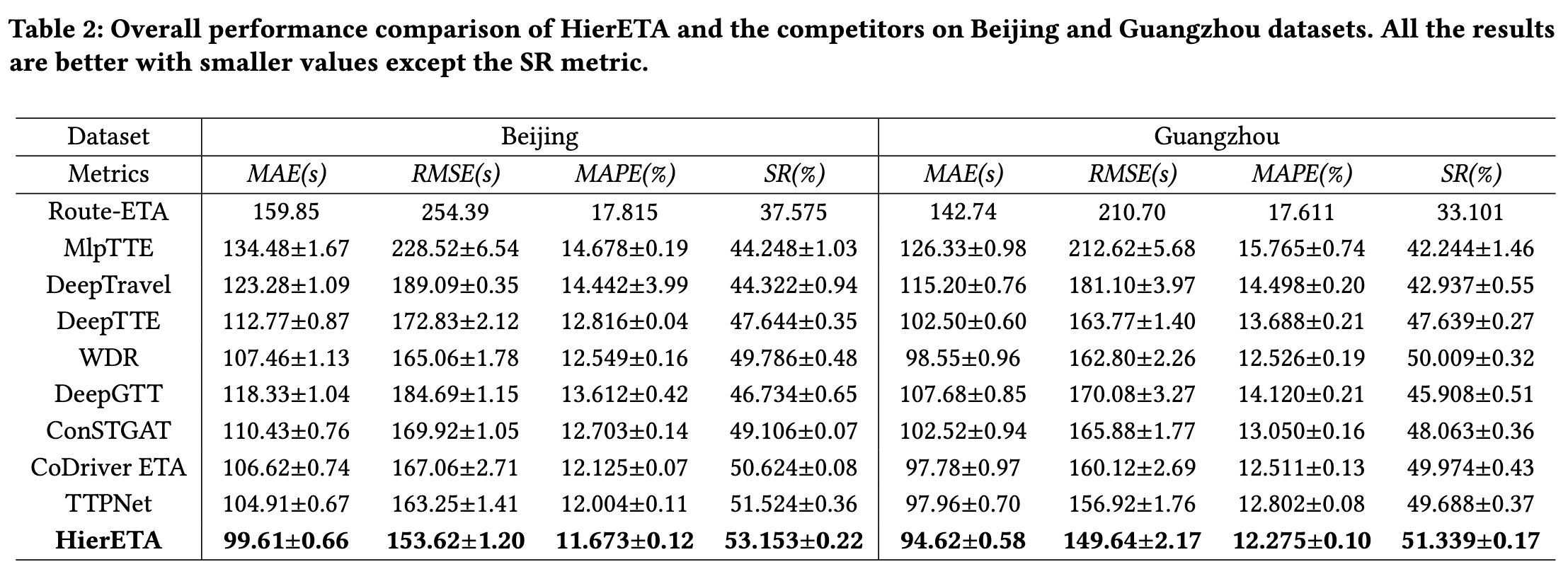
从北京的 mae 上来看比其他方法好 5s 以上,更进一步分析,里程比较长的单提升效果更明显。
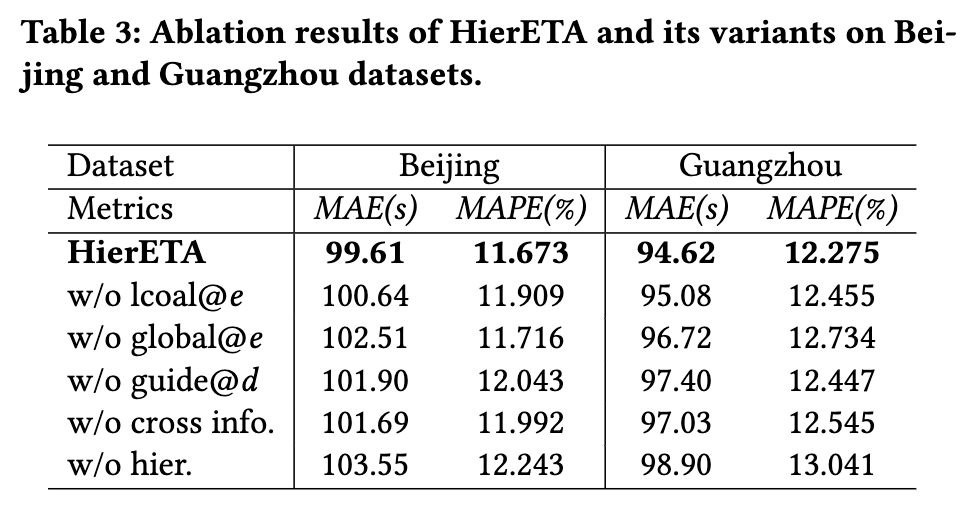
消融实验方法:有无 local 和 global 特征、有无路况信息、由于层次化结构等。mae 超过 1s 可以认为变化很大。
读后总结
- 层次化建模然后在利用 link 的 attention 对 segment 的 attention score 进行调整挺有意思的
- 遗憾没有线上实验结果,以及没有开放相关数据集,感觉 ETA 任务各家都有自己的数据集,然后不同方法之间没有太强横向可比性
【滴滴 HierETA】Interpreting Trajectories from Multiple Views A Hierarchical Self-Attention Network for Estimating the Time of Arrival