【Uber ETA】DeeprETA An ETA Post-processing System at Scale
本篇文章充满工业界风格,介绍 Uber 如何构建基于深度学习的 ETA 系统。在 Uber App 中,ETA 主要服务网约车和外卖两大业务,基于业务发展产生出一些细分场景的 ETA 需求(pick-up、drop-off)。技术挑战在于偏航(系统预估路线和司机真实路线不同)、不同场景数据分布不同、不同场景对 ETA 诉求不同,所以他们主要目标是构建高效以及泛用的 ETA 系统。
背景介绍
为了更充分了解相关背景知识,也可以看看我之前写的滴滴 ETA 论文解读 (WDR) Learning to Estimate the Travel Time)
ETA (Estimated Time of Arrival,预估到达时间):给定时刻下,预估从一个起点到终点所需要的时间。ATA (Actual Time Of Arrival,真实到达时间):给定时刻下,真实从一个起点到终点花费的时间。ETA 任务的目标是最小化 ETA 和 ATA 的差距,一般用 MAPE 或 MAE 来衡量。
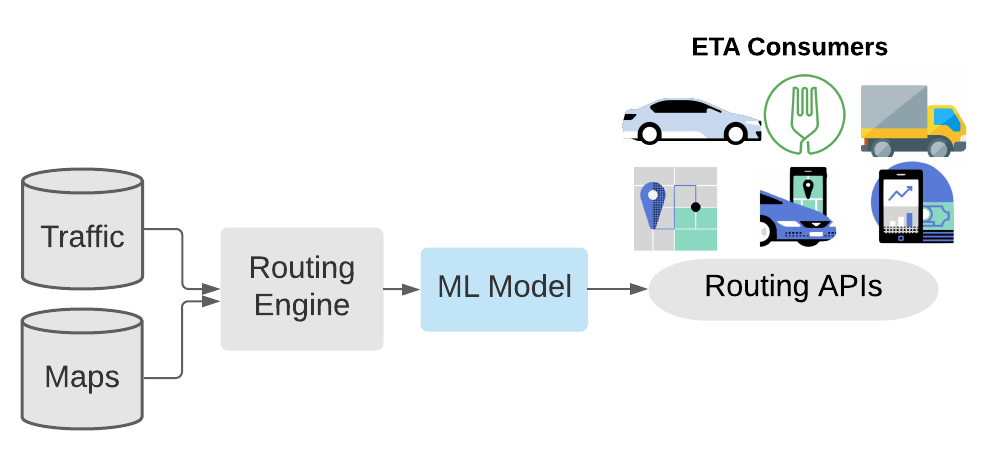
上图是 Uber ETA Posting-processing System,主要包括四部分:
Maps & Traffic: Map 指将整个真实世界用图数据(点和边)来建模。在给定起点和终点的情况下,路径规划系统规划的路线可以用一系列边来表示。Traffic 指交通状态,路况团队会根据前一段时间收集到的 gps 信号,预计后面一段时间内真实世界中道路的拥堵程度和通行速度。Routing Engine:根据路径规划系统规划的路线以及路况发布的道路通行速度计算出一个规则 ETA(Routing Engine ETA, RE-ETA)ML Model:本文介绍的深度学习 DeeprETA 模型,该模型预估 RE-ETA 和 ATA 的残差。Routing APIs:通过 api 接口给其他业务提供 ETA 服务
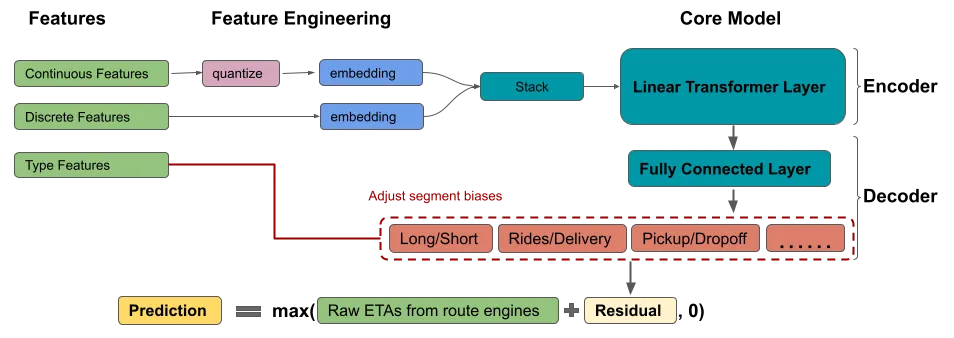
DeeprETA
遵循 More Embeddings, Fewer Layers 原则,设计预测效率更高的模型,主要包括 embdding module 和 2-Layer Module 两个模块。
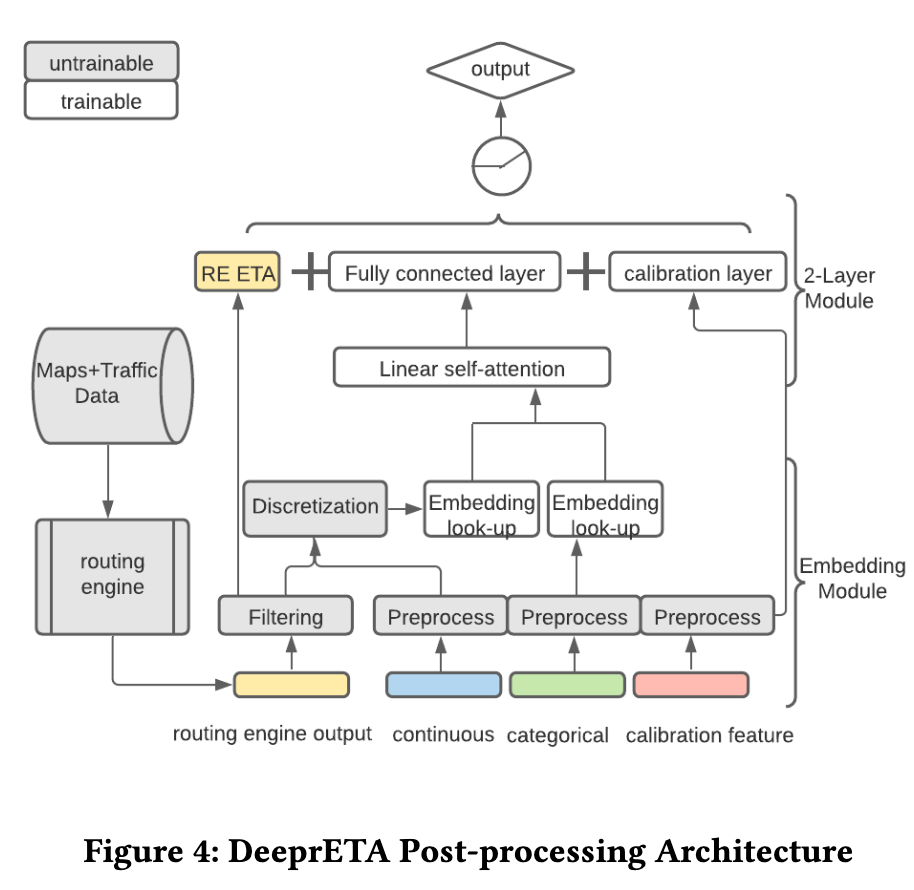
Embedding module
模型特征主要分成三类:Continuous Features、Categorical Features 以及 Geospatial Features,具体特征如下:
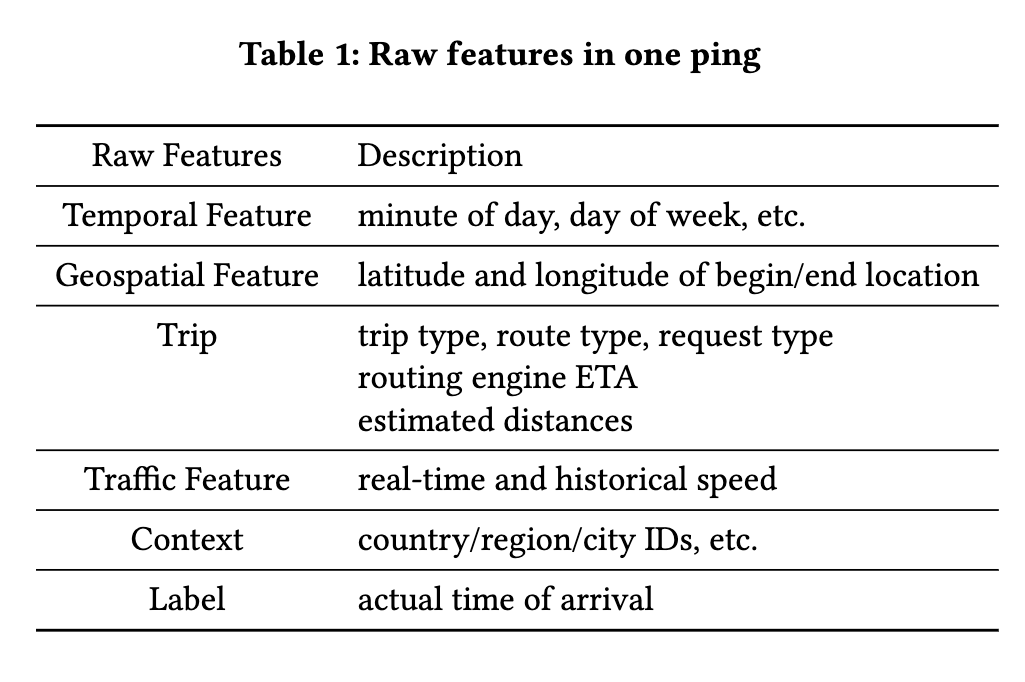
Categorical Features
所有类别特征都 embedding 化
Continuous Features
数值特征先分桶离散化,然后转成 embeddine。作者他们尝试发现 quantile buckets(等频分桶,比如每 20% 样本分一个同) 比 equal-width buckets(等距分桶)效果更好,猜测其可能原因是等频分桶更有效保留信息(We suspect that quantile buckets perform well because they maximize entropy: for any fixed number of buckets, quantile buckets convey the most information (in bits) about the original feature value compared to any other bucketing scheme.)。
Geospatial Features
Geospatial Features 主要指终点和起点的经纬度坐标,通过 geo hashing + multiple feature hashing 转换成 embdding。
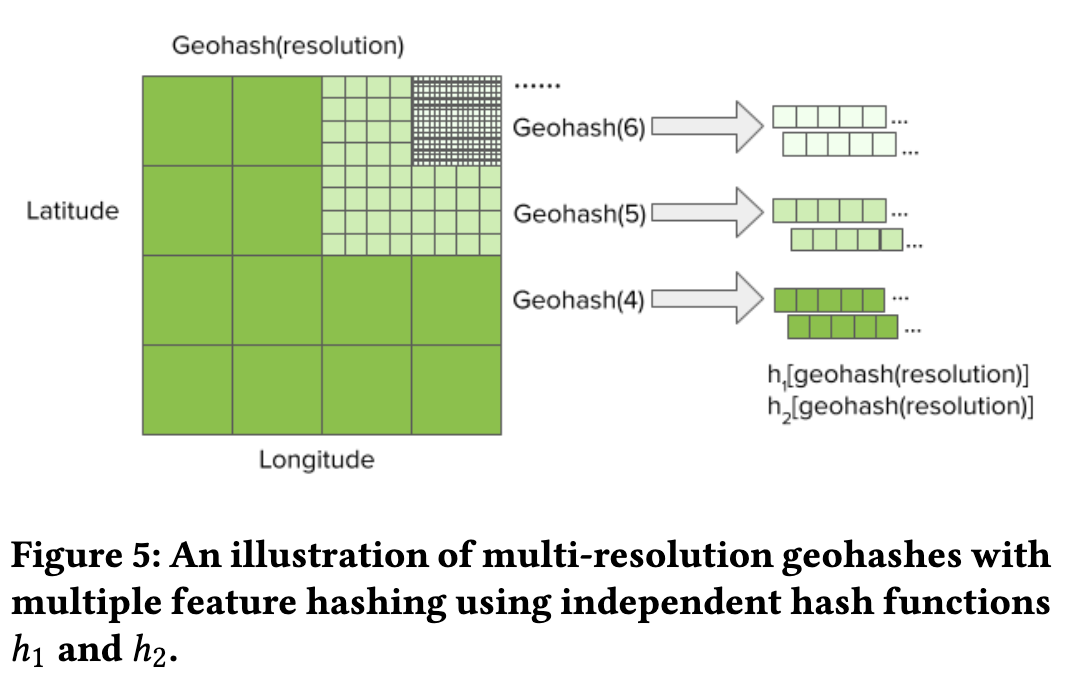
- 通过 Geohash 将经纬度转换成固定长度的字符串
- 将
lat, lng转换成[0,1]范围内浮点数 - 放大上一步得到的浮点数到
[0, 2e32]转换成 32 位整数 - 将 lat 和 lng 对应的两个 32 整数合并成一个 64 位整数
- 利用 base32 对 64 位整数进行编码得到一个长度为
5ubits 的字符串
- 将
- 通过 Feature hasing 将字符串转换成 index
Exact indexing每个字符串转成单独 embdding。geohash 精度越高,该方法内存消耗越大。Multiple feature hashingfeature hashing 将多个字符串转换成一个 index。考虑到hash冲突以及格子内订单的热度,同一个字符串使用多个 hash 函数处理得到多个 index。
2-layer Module
2-layer Module 分别是 Interaction layer 和 Calibration layer。模型 ETA 可以表示成:
其中 f 代表 Interaction layer,f2 代表全连层, 代表 Calibration layer (第 j 种类型 ETA 的偏置)。
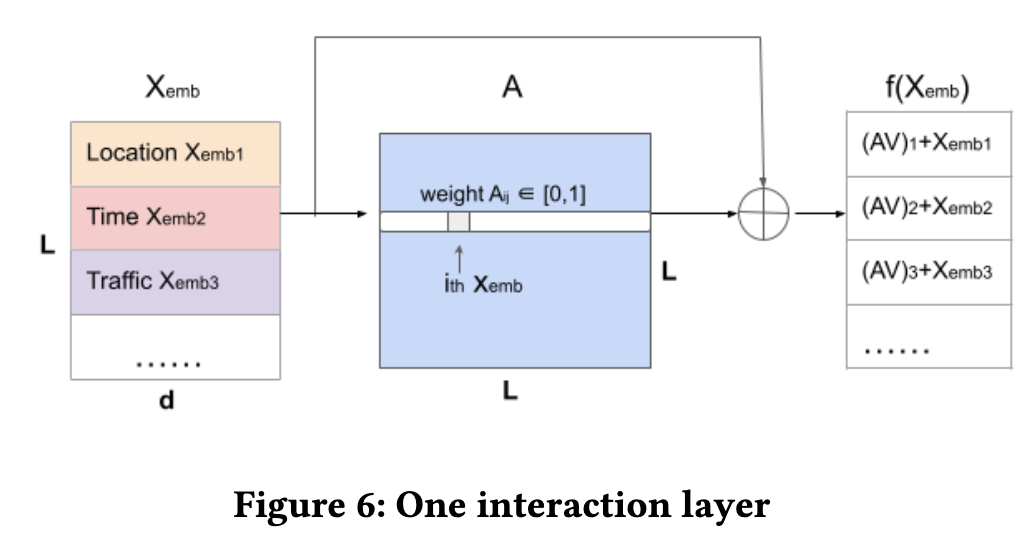
Interaction layer
所有特征在经过 Embedding module 后。都被转换成相同长度的 embdding,然后经过 Interaction layer 进行特征交叉。尝试过主流的网络结构后,作者选择的是 self-attention 结构,更进一步引入 Linear self-attention 解决 attention 矩阵计算速度慢的问题。
Calibration layer
针对不同业务数据分布特点,Calibration layer 根据ETA请求类型(网约车/配送、pickup/dropoff、长短单)使用全连接层对上一步模型结果进行校准(对预测结果进行整体偏移)。另外,作者也提到这一层也可以设计成 MMoE 结构。
Asymmetric Huber loss function
不同类型 ETA 任务需要用不同的指标来评估,比如预估价格需要 ETA mean erros,配送 ETA 利用类似于 95th 更加合理。所以作者设计出一种非对称的 Huber Loss Fucntion:
代表模型参数, 控制模型对高低估倾向(比如准时赔场景,如果模型低估严重会带来大量投诉), 控制异常值的容忍程度,值越大对异常值越不敏感。
Train
- 每周训练模型
- Adam
- Relative cosine annealing learning rate scheduler
实验效果
评估指标
主要有 mean absolute error (MAE), 50th percentile absolute error (p50 error) and 95th percentile absolute error (p95 error)。实验结果都是计算三个指标相对于 RE-ETA 的提升。比如 MAE 的计算方式改成:
结果
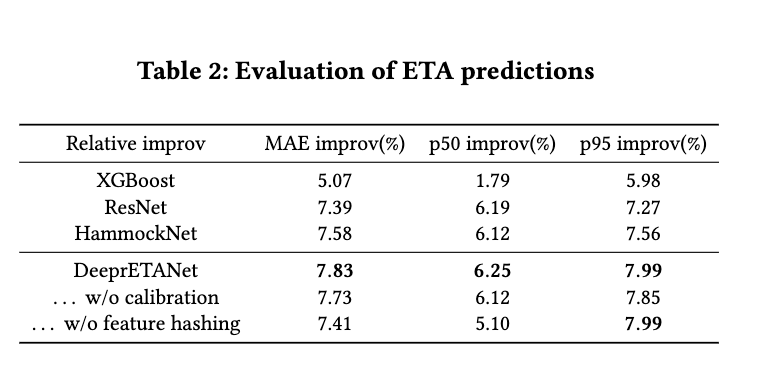
- DeeprETANet 比 XGBoost ResNet HammockNet 等方法都有明显的效果提升。
- 在 p95 指标上 DeeprETANet 和无 feature hashing DeeprETANet 提升相类似,可能说明 geospatial embeddings 能在 type case 上有提升,但是不能改善极端错误的情况。
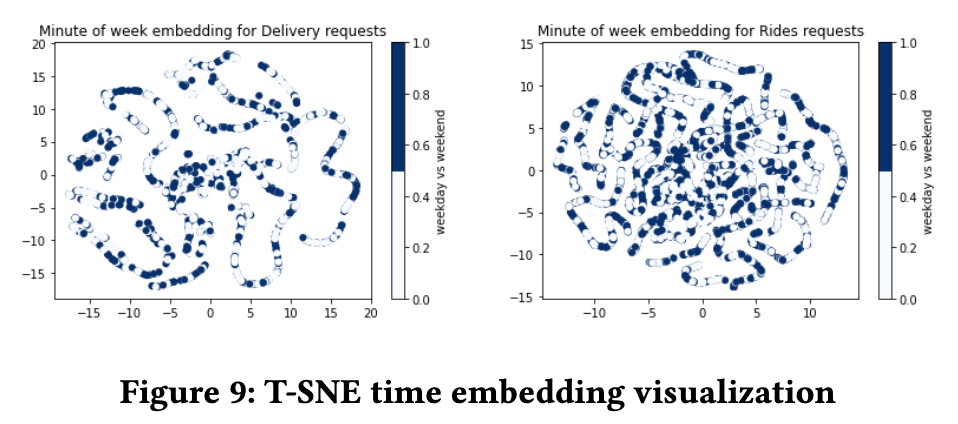
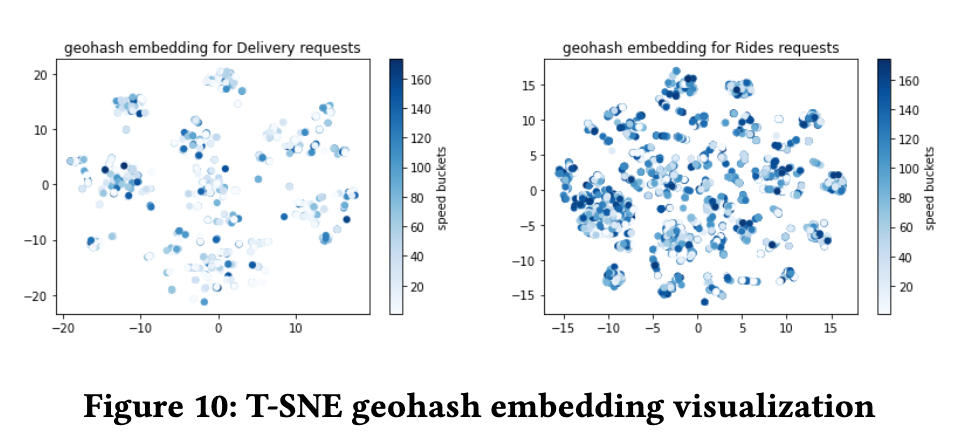
Embedding Analysis
这一部分作者用 t-SNE (将 embedding 降维到 2维)对 geospatial embeddings 和 temporal embedding 进行分析。
temporal embedding
两幅图分别是配送和网约车的 embedding 分布,深色代表 weekend,浅色代表 weekday,从图上看有局部连续性,但是没有明确的周末或工作日效应(深色和浅色没有明显聚集)
geospatial embeddings
geospatial embeddings 有局部聚集性,猜测是相邻的位置有相似的表示。配送和网约车学习到的 embedding 不同。
参考
【Uber ETA】DeeprETA An ETA Post-processing System at Scale