generalization 指的是通过泛化出现过特征从解释新出现特征的能力。常用的是将高维稀疏的特征转换为低维稠密 embedding 向量,然后使用 fm 或 dnn 等算法。与 LR 相比,减少特征工程的投入,而且对没有出现过的组合有较强的解释能力。但是当遇到的用户有非常小众独特的爱好时(对应输入的数据非常稀疏和高秩),模型会过度推荐。
综合前文 ,作者提出一种新的模型 Wide & Deep。
模型
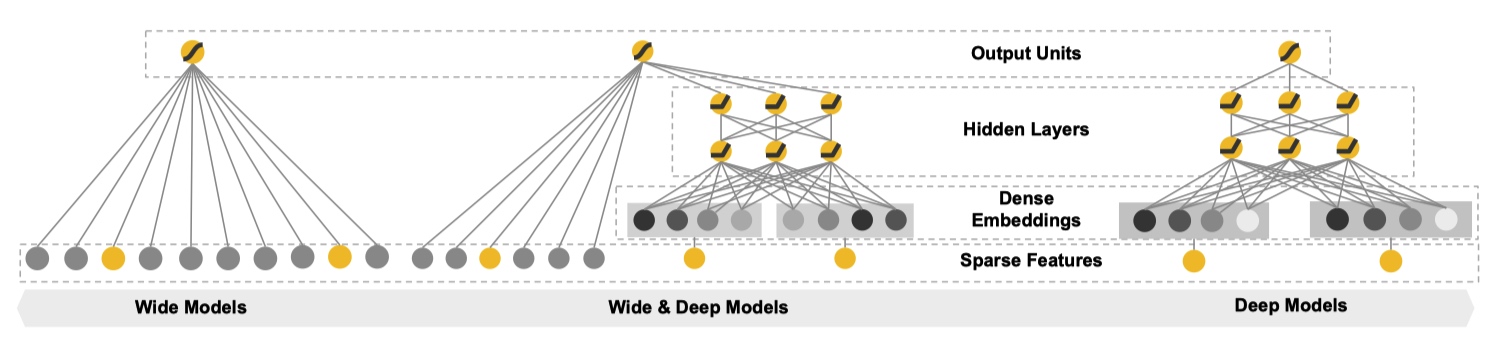
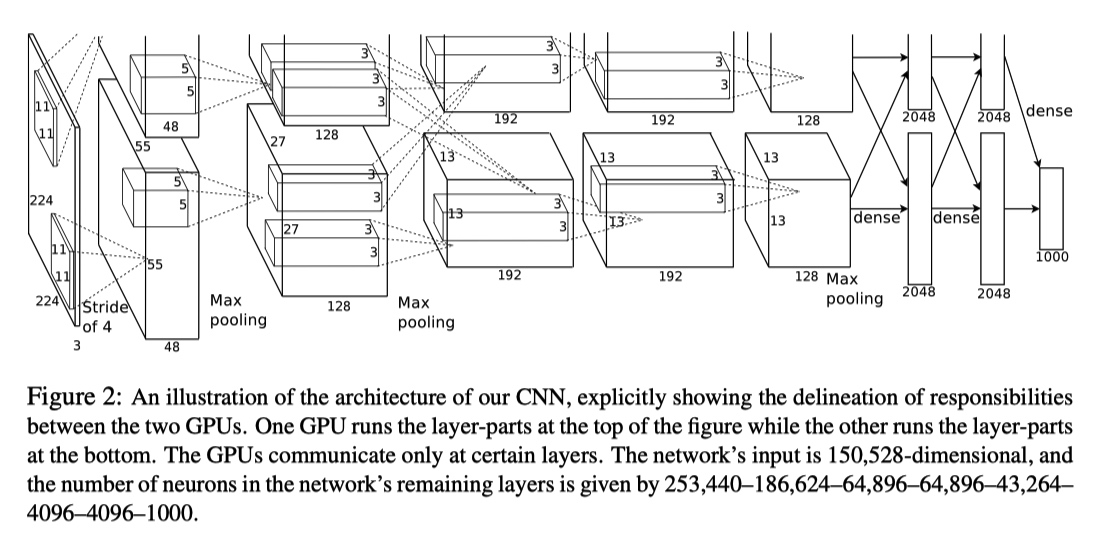
从文章题目中顾名思义,Wide & Deep 是融合 Wide Models 和 Deep Models 得到,下图形象地展示出来。
Wide Component 是由一个常见的广义线性模型:y=wTx+b。其中输入的特征向量 x 包括两种类型:原始输入特征(raw input features)和组合特征(transformed features)。
常用的组合特征公式如下:
ϕk(x)=i=1∏dxicki,cki∈{0,1}
cki 代表对于第k个组合特征是否包含第i个特征。xi是布尔变量,代表第i个特征是否出现。例如对于组合特征 AND(gender=female, language=en) 当且仅当 x 满足(“gender=female” and “language=en”)时,ϕk(x)=1。
Deep Component 是一个标准的前馈神经网络,每一个层的形式诸如:a(l+1)=f(W(l)a(l)+b(l))。对于输入中的 categorical feature 需要先转化成低维稠密的 embedding 向量,再和其他特征一起喂到神经网络中。
对于这种由基础模型组合得到的新模型,常用的训练形式有两种:joint training 和 ensemble。ensemble 指的是,不同的模型单独训练,且不共享信息(比如梯度)。只有在预测时根据不同模型的结果,得到最终的结果。相反,joint training 将不同的模型结果放在同一个损失函数中进行优化。因此,ensmble 要且模型独立预测时就有有些的表现,一般而言模型会比较大。由于 joint training 训练方式的限制,每个模型需要由不同的侧重。对于 Wide&Deep 模型来说,wide 部分只需要处理 Deep 在低阶组合特征学习的不足,所以可以使用简单的结果,最终完美使用 joint traing。
预测时,会将 Wide 和 Deep 的输出加权得到结果。在训练时,使用 logistic loss function 做为损失函数。模型优化时,利用 mini-batch stochastic optimization 将梯度信息传到 Wide 和 Deep 部分。然后,Wide 部分通过 FTRL + L1 优化,Deep 部分通过 AdaGrad 优化。
ATAL Something's wrong. Maybe you can find the solution here: http://hexo.io/docs/troubleshooting.html SyntaxError: Unexpected token h in JSON at position 30 at JSON.parse (<anonymous>) at /Users/didi/Documents/personal/xiang578.github.io/node_modules/hexo-leancloud-counter-security/index.js:92:42 at arrayEach (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_lodash@4.17.11@lodash/lodash.js:516:11) at Function.forEach (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_lodash@4.17.11@lodash/lodash.js:9344:14) at Hexo._callee$ (/Users/didi/Documents/personal/xiang578.github.io/node_modules/hexo-leancloud-counter-security/index.js:83:27) at tryCatch (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:62:40) at Generator.invoke [as _invoke] (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:296:22) at Generator.prototype.(anonymous function) [as next] (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:114:21) at step (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_babel-runtime@6.26.0@babel-runtime/helpers/asyncToGenerator.js:17:30) at /Users/didi/Documents/personal/xiang578.github.io/node_modules/_babel-runtime@6.26.0@babel-runtime/helpers/asyncToGenerator.js:28:13 at process._tickCallback (internal/process/next_tick.js:68:7)
y = JSON.parse(memoData[memoIdx].substring(0, memoData[memoIdx].length - 1));
js 没有怎么接触过,不知道能不能单步调试之类的,只好祭出输出调试大法,加上两个输出:
1 2 3
console.log(memoIdx) console.log(memoData[memoIdx]) y = JSON.parse(memoData[memoIdx].substring(0,memoData[memoIdx].length - 1));
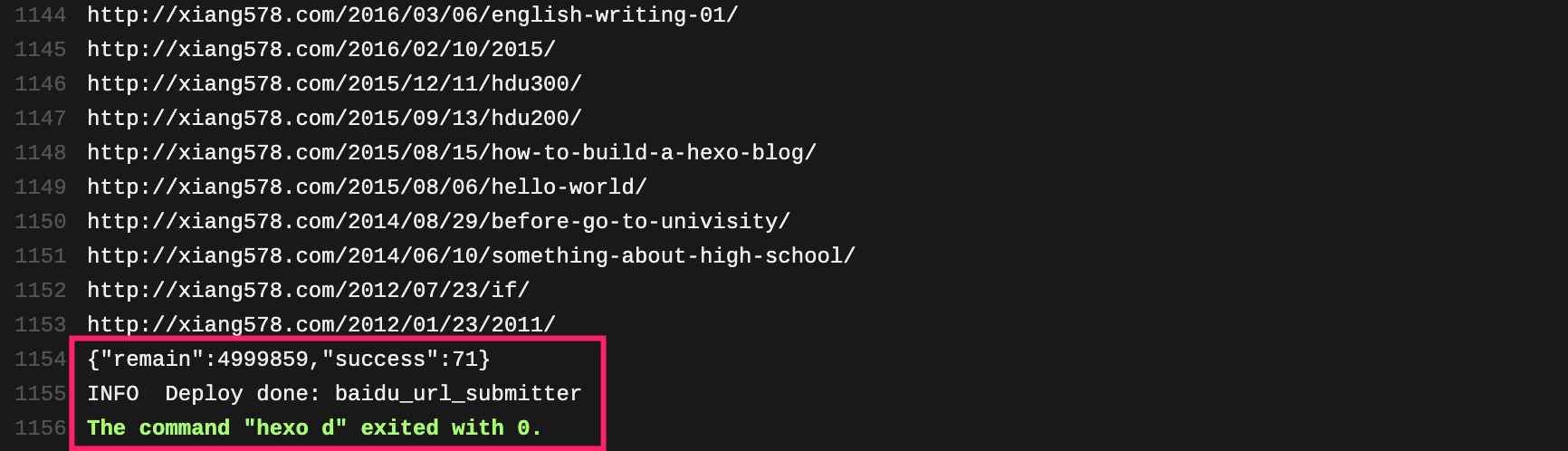
然后再执行 hexo -d 命令,命令行输出为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
28 {"title":"System.out.println("hello world!");","url":"/post/hello-world.html"}, FATAL Something's wrong. Maybe you can find the solution here: http://hexo.io/docs/troubleshooting.html SyntaxError: Unexpected token h in JSON at position 30 at JSON.parse (<anonymous>) at /Users/didi/Documents/personal/xiang578.github.io/node_modules/hexo-leancloud-counter-security/index.js:92:42 at arrayEach (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_lodash@4.17.11@lodash/lodash.js:516:11) at Function.forEach (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_lodash@4.17.11@lodash/lodash.js:9344:14) at Hexo._callee$ (/Users/didi/Documents/personal/xiang578.github.io/node_modules/hexo-leancloud-counter-security/index.js:83:27) at tryCatch (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:62:40) at Generator.invoke [as _invoke] (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:296:22) at Generator.prototype.(anonymous function) [as next] (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_regenerator-runtime@0.11.1@regenerator-runtime/runtime.js:114:21) at step (/Users/didi/Documents/personal/xiang578.github.io/node_modules/_babel-runtime@6.26.0@babel-runtime/helpers/asyncToGenerator.js:17:30) at /Users/didi/Documents/personal/xiang578.github.io/node_modules/_babel-runtime@6.26.0@babel-runtime/helpers/asyncToGenerator.js:28:13 at process._tickCallback (internal/process/next_tick.js:68:7)